背景:强化学习在大语言模型推理中的潜力与挑战
强化学习(RL)在提升大语言模型(LLM)推理能力方面展现出巨大潜力,但存在信用分配问题,即如何将整个序列最终的评估结果归因到序列中具体的决策动作。这一问题的困难在于奖励信号稀疏,只能在序列结束时获得明确反馈。
大模型强化学习新突破:SPO 新范式助力大模型推理能力提升!
当前方法:粗粒度与细粒度优势值估计的局限性
-
粗粒度的轨迹级方法 :如 DeepSeek R1 使用的 GRPO,只根据最终奖励为整个序列计算一个优势值,反馈信号粗糙,无法对错误回答中的正确部分给予奖励或对正确回答中的冗余部分进行惩罚。
-
细粒度的 token 级方法 :如经典的 PPO,为每个 token 估计优势值,但依赖额外的 critic 模型,且在大语言模型的强化学习任务中,由于不同 prompt 对应的轨迹分布差异大、训练过程每个 prompt 采样出来的模型回复数量有限,导致 critic 模型难以训练好,优势值估计误差大。
新的 SPO 框架:中等粒度的段级优势值估计方案
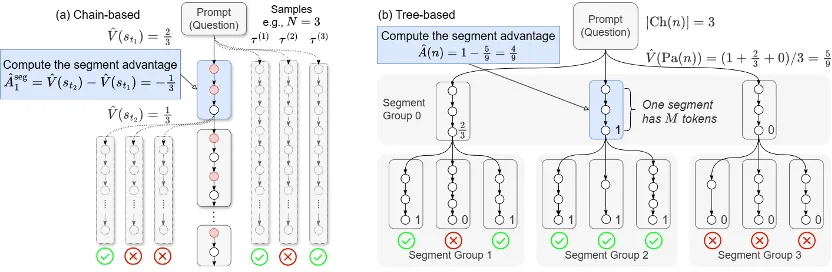
中科院软件所和香港城市大学的研究团队提出了 Segment Policy Optimization (SPO) 框架,采用中等粒度的段级优势值估计方式,将生成的序列划分为若干相连的段,计算每个段的优势值。
SPO 框架的核心优势
-
更优的信用分配 :相比轨迹级方法,段级方法提供更局部化的优势反馈,能奖励错误回答中仍有价值的部分,惩罚正确回答中冗余和无效的片段。
-
更准确的优势值估计 :相比 token 级方法,段级方法估计点数量少,有效利用蒙特卡洛采样得到更准确且无偏的优势值估计,无需依赖额外且不稳定的 critic 模型。
-
更灵活、更易调整 :段级划分方式可任意定义,不需语义完整性,能在 token 级与轨迹级之间自由调整粒度,适应不同任务和应用场景。
SPO 框架的核心部分
-
灵活的段级划分策略 :
-
基于切分点的段划分 :为短思维链场景设计,将段划分点放置在状态值更有可能发生变化的地方,根据 token 概率动态确定段边界,优先在模型 “犹豫” 或可能改变推理路径的关键点进行划分,使信用分配更精确。
-
固定 token 数量段划分 :将序列划分为固定长度的段,便于树形结构的组织和优势值估计,为 SPO-tree 设计。
-
-
基于蒙特卡洛采样的段级优势值估计 :
-
链式优势值估计 :在短思维链场景下,MC 采样成本不高,采用直接的段级优势值估计方式,独立估计每个段边界的状态值,然后计算段级优势值。
-
树形优势值估计 :在长思维链场景下,MC 估计代价高,提出高效的树形估计方法,将采样轨迹组织成树形结构,通过自底向上的奖励聚合计算状态价值,同一个父节点的子节点形成一个组,在组内计算每个段的优势值。
-
-
利用段级优势值进行策略优化 :提出 token 概率掩码策略优化方法,选择性地对段内的低概率 token 计算损失而非段内的所有 token,将奖励 / 惩罚更精确地赋予关键决策点,提升学习效率和效果。
SPO 框架的实例
-
SPO-chain :针对短思维链场景,使用基于切分点的段划分和链式优势值估计。
-
SPO-tree :针对长思维链场景,采用极大提升 MC 采样效率的树形结构优势值估计方法。
实验验证:SPO 框架的有效性
-
与基线方法对比 :在短思维链场景下,使用 RhoMath1.1B 作为基座模型,SPO 训练得到的模型测试集正确率更高;在长思维链场景下,使用 DeepSeek-R1-Distill-Qwen-1.5B 作为基座模型,相同训练时间内,SPO-tree 测试集正确率比 GRPO 更高。
-
分段粒度影响 :很细的粒度相比于中等粒度仅有微小提升,但过粗的粒度相比于中等粒度正确率下降很大,证明 SPO 采用中等粒度优势值的有效性。
-
段划分方式影响 :短思维链场景下,基于切分点的段划分方式效果优于采用换行符进行划分以及固定 token 数量划分。
-
Token 概率掩码消融 :去除 token 概率掩码会导致 SPO-chain 正确率下降,将 token 概率掩码应用到 GRPO 上,其正确率有明显上升。
-
不同树结构影响 :更小的树结构在早期正确率更高,但随着训练进行,更大的树结构正确率更好。
总结
SPO 框架在 token 级和轨迹级之间取得更好的平衡,具有比轨迹级更好的信用分配,仅需少量优势值估计点,可使用有效无偏的 MC 方式进行估计,无需额外的 critic 模型。该框架及其两个实例 SPO-chain 和 SPO-tree 在提升大语言模型推理能力方面展现出显著优势。



